Service optimisation SEO WordPress: l'audit Lighthouse
Formulaire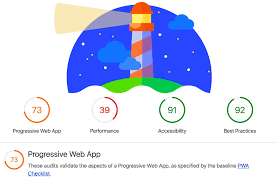
Découvrez dans cette série de quatre articles les points éxaminés par l’outil de référence Google, Google Lighthouse pour déterminer la qualité de votre site (et donc son référencement)
AUDIT SEO
Les vérifications ci-dessous permettent de s’assurer que la page respecte les conseils de base en matière d’optimisation des moteurs de recherche. Découvrez ci-dessous les performances Google Lighthouse de mon site:
- META DONNEES
Le contenu de l’en-tête HTML <head> — à la difference du contenu de l’élément <body> (affiché quand la page est chargée par le navigateur) — n’est pas affiché dans la page du navigateur. Le travail de la balise <head> est de contenir les métadonnées à propos du document. Dans l’exemple ci-dessus, l’en-tête est plutôt petit :
<head>
<meta charset=« utf-8« >
<title>Ma page test</title>
</head>
Une balise `<meta name= »viewport »>` optimise non seulement votre application pour les tailles d’écran mobiles, mais évite également un délai de 300 millisecondes pour la saisie de l’utilisateur. En savoir plus.
- Has a
<meta name="viewport">tag withwidthorinitial-scale
- Le document comporte un élément <title>
La présence d’un élément <title> sur chaque page aide tous vos utilisateurs :
Les utilisateurs de moteurs de recherche se fient au titre pour déterminer si une page est pertinente pour leur recherche.
Le titre donne également aux utilisateurs de lecteurs d’écran et d’autres technologies d’assistance un aperçu de la page. Le titre est le premier texte qu’une technologie d’assistance annonce.
Comment la vérification du titre de Lighthouse échoue ?
Lighthouse signale les pages sans élément <title> dans le <head> de la page.
- Le document a une méta-description
- Page has successful HTTP status code
Votre serveur web ne retourne pas d’erreur (ex de type 404) à la requette client.
- Les liens ont un texte descriptif
<p>To see all of our basketball videos, <a href="videos.html">click here</a>.</p><p>Check out all of our <a href="videos.html">basketball videos</a>.</p>- Les liens peuvent être explorés
Google ne pas suivre les liens suivants:
<a routerLink="some/path"><span href="https://example.com"><a onclick="goto('https://example.com')">
<a href="https://example.com"><a href="/relative/path/file">
- La page n’est pas bloquée pour l’indexation
Lighthouse vérifie uniquement les en-têtes ou les éléments qui bloquent tous les robots des moteurs de recherche. Par exemple, l’élément <meta> ci-dessous empêche tous les crawlers des moteurs de recherche (également appelés robots) d’accéder à votre page :
<meta name="robots" content="noindex"/>- robots.txt est valide
Comment résoudre les problèmes liés à robots.txt ?
Assurez-vous que le fichier robots.txt ne renvoie pas un code d’état HTTP 5XX.
Si votre serveur renvoie une erreur de serveur (un code d’état HTTP de type 500) pour robots.txt, les moteurs de recherche ne sauront pas quelles pages doivent être explorées. Ils risquent d’arrêter l’exploration de l’ensemble de votre site, ce qui empêcherait l’indexation du nouveau contenu.
Pour vérifier le code d’état HTTP, ouvrez robots.txt dans Chrome et vérifiez la requête dans Chrome DevTools.
Faites en sorte que le fichier robots.txt soit inférieur à 500 KiB #.
Les moteurs de recherche peuvent arrêter de traiter le fichier robots.txt à mi-chemin si sa taille est supérieure à 500 Ko. Cela peut perturber le moteur de recherche et entraîner une mauvaise exploration de votre site.
Pour que le fichier robots.txt reste petit, concentrez-vous moins sur les pages exclues individuellement et plus sur des modèles plus larges. Par exemple, si vous devez bloquer l’exploration des fichiers PDF, n’interdisez pas chaque fichier individuellement. Au lieu de cela, interdisez toutes les URL contenant des .pdf en utilisant disallow : /*.pdf.
Corrigez toutes les erreurs de format
Seules les lignes vides, les commentaires et les directives correspondant au format « name : value » sont autorisés dans le fichier robots.txt.
Assurez-vous que les valeurs allow et disallow sont vides ou commencent par / ou *.
N’utilisez pas de $ au milieu d’une valeur (par exemple, allow : /file$html).
Assurez-vous qu’il y a une valeur pour user-agent #.
Les noms d’agents utilisateurs indiquent aux robots d’exploration des moteurs de recherche les directives à suivre. Vous devez fournir une valeur pour chaque instance de user-agent afin que les moteurs de recherche sachent s’ils doivent suivre l’ensemble des directives associées.
Pour spécifier un moteur de recherche particulier, utilisez un nom d’agent utilisateur dans sa liste publiée. (Par exemple, voici la liste des user-agents utilisés par Google pour l’exploration).
Utilisez * pour faire correspondre tous les crawlers qui ne le seraient pas autrement.
Ne pas utiliser
user-agent :
disallow : /downloads/
Aucun agent utilisateur n’est défini.
Faites
user-agent : *
disallow : /downloads/
user-agent : magicsearchbot
rejeter : /uploads/
Un agent utilisateur général et un agent utilisateur magicsearchbot sont définis.
Assurez-vous qu’il n’y a pas de directives allow ou disallow avant user-agent #.
Les noms des agents utilisateurs définissent les sections de votre fichier robots.txt. Les robots des moteurs de recherche utilisent ces sections pour déterminer les directives à suivre. Placer une directive avant le premier nom d’agent utilisateur signifie qu’aucun robot d’exploration ne la suivra.
A ne pas faire
# début du fichier
disallow : /downloads/
user-agent : magicsearchbot
allow : /
Aucun robot d’exploration de moteur de recherche ne lira la directive disallow : /downloads.
Faites
# début du fichier
agent utilisateur : *
disallow : /downloads/
Tous les moteurs de recherche ne sont pas autorisés à explorer le dossier /downloads.
Les moteurs de recherche ne suivent que les directives de la section contenant le nom d’agent utilisateur le plus spécifique. Par exemple, si vous avez des directives pour user-agent : * et user-agent : Googlebot-Image, Googlebot Images ne suivra que les directives de la section user-agent : Googlebot-Image.
Fournissez une URL absolue pour le sitemap #.
Les fichiers sitemap sont un excellent moyen de faire connaître aux moteurs de recherche les pages de votre site Web. Un fichier sitemap comprend généralement une liste des URL de votre site Web, ainsi que des informations sur la date de leur dernière modification.
Si vous choisissez de soumettre un fichier sitemap dans le fichier robots.txt, veillez à utiliser une URL absolue.
N’utilisez pas
sitemap : /sitemap-file.xml
Faire
sitemap : https://example.com/sitemap-file.xml
- Les éléments d’image ont des attributs [alt].
<img alt="Audits set-up in Chrome DevTools" src="...">- Le document a un hreflang valide
Il existe trois façons d’indiquer aux moteurs de recherche que ces pages sont équivalentes. Choisissez la méthode la plus simple pour votre situation.
Option 1 : ajoutez des liens hreflang dans le <head> de chaque page :
<link rel= »alternate » hreflang= »en » href= »https://example.com » />
<link rel= »alternate » hreflang= »es » href= »https://es.example.com » />
<link rel= »alternate » hreflang= »de » href= »https://de.example.com » />
- Le document a une rel=canonical valide
Lorsque plusieurs pages ont un contenu similaire, les moteurs de recherche les considèrent comme des versions dupliquées de la même page. Par exemple, les versions desktop et mobile d’une page produit sont souvent considérées comme des doublons.
Les moteurs de recherche sélectionnent l’une des pages comme version canonique, ou principale, et l’explorent davantage. Les liens canoniques valides vous permettent d’indiquer aux moteurs de recherche la version d’une page à explorer et à afficher aux utilisateurs dans les résultats de recherche.
- Le document évite les plugins
Lighthouse vérifie la page à la recherche d’éléments qui représentent généralement des plugins :
embedobjectapplet
Lighthouse signale ensuite un élément comme étant un plugin si son type MIME correspond à l’un des éléments suivants :
application/x-java-appletapplication/x-java-beanapplication/x-shockwave-flashapplication/x-silverlightapplication/x-silverlight-2
Lighthouse signale également les éléments qui pointent vers une URL dont le format de fichier est connu pour représenter un contenu de plugin :
swfflvclassxap
N’utilisez pas de plugins pour afficher votre contenu
Toujours concernant la création de sites web:
Formulaire de création de site web

Front end Designers
Téléphone: (33)06.52.68.09.20
Web Designers
Services digitaux et Web - Créations de sites web vitrines et E-commerces optimasations de sites.
